- Добро пожаловать на Сообщество Cyfertalk.

Последние сообщения
#11
Обнаружение багов и предложения фич / От: отмена действия
Последний ответ от Администратор - Апр. 09, 2024, 03:32Цитата: Нурия от Апр. 09, 2024, 10:18 удаляя слова, удалила все буквыВы нажали кнопку "Удалить всё", она удаляет все Слова, после чего вылетает диалог "Удалить Буквы?", если нажать "Подтвердить", то Буквы тоже удалятся, а если "Отменить" то нет.
Цитата: Нурия от Апр. 09, 2024, 10:18 или нужно периодически сохраняться? как?Можно пользоваться клавишами F5(быстрое сохранение) и F9(быстрая загрузка) в Планшете, либо сохранять/загружать архивные копии базы из Стартовой формы
#12
Справка и часто задаваемые вопросы / При установке появляется преду...
Последний ответ от Администратор - Апр. 09, 2024, 10:44Если при установке/запуске программы вы видите окно:
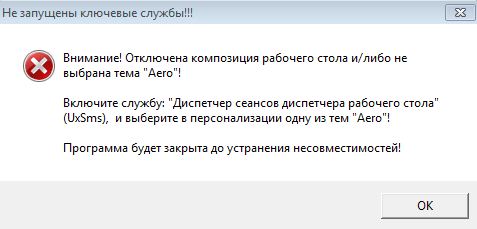
значит вы устанавливаете/запускаете CYFERTALK в Windows 7 с отключенным диспетчером окон рабочего стола.
Это ключевая технология, без которой запуск CYFERTALK в операционной системе Windows невозможен.
Проблема может возникнуть только в версии Windows 7, потому что на более поздних версиях Windows диспетчер окон рабочего стола включён по умолчанию как часть системы и не может быть отключён, в отличии от Windows 7.
Для того чтобы включить диспетчер окон рабочего стола, вам необходимо открыть настройки персонализации рабочего стола и выбрать одну из тем Aero:
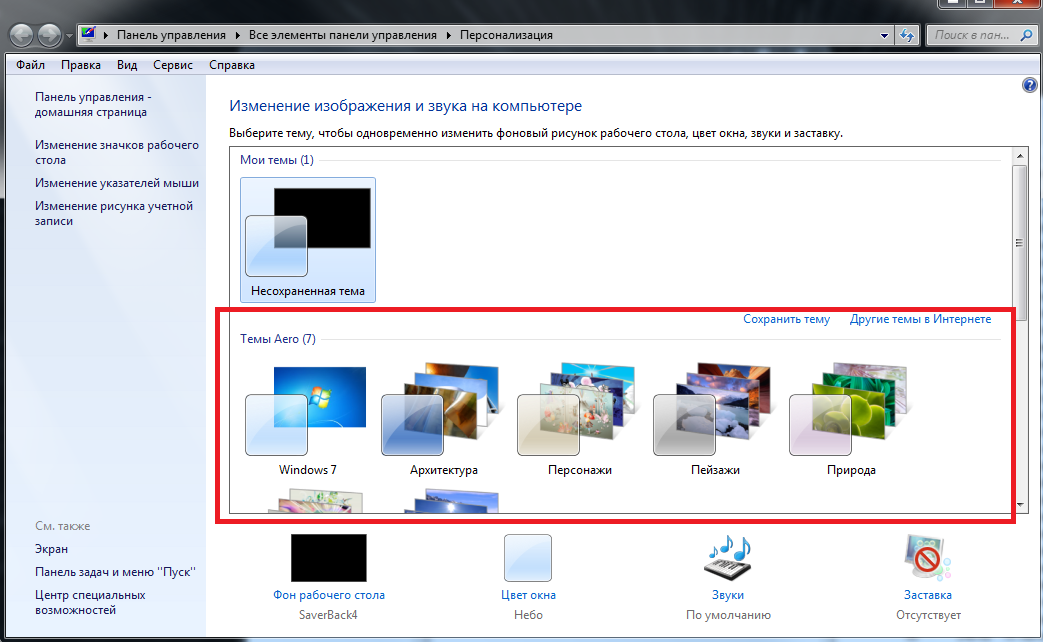
После этого диспетчер окон рабочего стола будет запущен и CYFERTALK сможет функционировать.
значит вы устанавливаете/запускаете CYFERTALK в Windows 7 с отключенным диспетчером окон рабочего стола.
Это ключевая технология, без которой запуск CYFERTALK в операционной системе Windows невозможен.
Проблема может возникнуть только в версии Windows 7, потому что на более поздних версиях Windows диспетчер окон рабочего стола включён по умолчанию как часть системы и не может быть отключён, в отличии от Windows 7.
Для того чтобы включить диспетчер окон рабочего стола, вам необходимо открыть настройки персонализации рабочего стола и выбрать одну из тем Aero:
После этого диспетчер окон рабочего стола будет запущен и CYFERTALK сможет функционировать.
#13
Обнаружение багов и предложения фич / Предложение по кнопке табуляци...
Последний ответ от Нурия - Апр. 09, 2024, 10:26хорошо бы сделать клавишу TAB активной для таблицы
#14
Обнаружение багов и предложения фич / Как отменить действие?
Последний ответ от Нурия - Апр. 09, 2024, 10:18есть при составлении букв и слов функция отмена действия? удаляя слова, удалила все буквы 
или нужно периодически сохраняться? как? или что то вроде восстановить всё. либо эти данные наверняка сохранены в файле
или нужно периодически сохраняться? как? или что то вроде восстановить всё. либо эти данные наверняка сохранены в файле
#15
Справка и часто задаваемые вопросы / Где найти справочные материалы...
Последний ответ от Администратор - Дек. 10, 2022, 07:31Краткий гайд по работе с программой можно найти в этом разделе под наименованием - Как работать в Cyfertalk?
Основные справочные материалы встроены в систему и открываются через все современные браузеры.
Справку по текущему окну программы можно открыть двумя способами:
В стартовом окне есть кнопка СПРАВКА, которая открывает справку со страницы введения.
Также ссылка на справку есть в меню на главной странице сайта.
Основные справочные материалы встроены в систему и открываются через все современные браузеры.
Справку по текущему окну программы можно открыть двумя способами:
- нажатием на символ вопроса в текущем окне
- нажатием клавиши F1
В стартовом окне есть кнопка СПРАВКА, которая открывает справку со страницы введения.
Также ссылка на справку есть в меню на главной странице сайта.
#16
Справка и часто задаваемые вопросы / Как работать в Cyfertalk ?
Последний ответ от Администратор - Дек. 09, 2022, 03:47Работа в Cyfertalk условно разбивается на 3 этапа:
Создание Алфавита.
Как можно понять из определения, Алфавит Cyfertalk - это набор специальных комбинаций символов, в терминологии Cyfertalk - Букв(признаков объектов и операций, помогающих точно определять объект и процесс.)
Буквы могут иметь один из трёх типов: группа, база и мера.
Различные комбинации Букв трёх типов образуют конечные идентификаторы бизнес процессов – Слова Cyfertalk , поэтому при разработке Алфавита, следует представлять, как Буквы будут комбинироваться и образовывать Слова.
Для разработки Слов существуют свои инструменты – формы Клонирования и Мутации, однако точность и правильность конечных идентификаторов могут гарантировать только верные порядок и содержание Алфавита.
Прежде чем приступать к построению Алфавита стоит уяснить несколько правил:
- Создавая модель, отталкивайтесь от целей её построения.
- Продумывайте наперед, какие операции будут производиться над объектами.
- Прежде чем приступать к конструированию Слов – точно выстраивайте Буквы по порядку(Вид), так как Буквы в Слове будут выстраиваться согласно номеру их Вида.
- Старайтесь избегать лишних Букв.
И последнее – прежде чем приступать к конструированию Слов, тщательно проверьте достаточность наполнения Алфавита , чтобы не приходилось создавать дополнительные Буквы уже в процессе моделирования.
Создание Словаря.
Словарь, как можно понять из его названия – это набор Слов(идентификаторов бизнес-процессов).
Порядок создания Слов может быть любым, проще всего начать с тех же Слов, с которых вы хотите начать создание первого представления модели(например: поступление оборудования, приход средств от инвесторов, выпуск продукта и т.д и т.п).
При конструировании Слов, стоит придерживаться нескольких правил:
- Подбирайте состав Слова максимально точно, не пропуская необходимых Букв и не добавляя лишних.
- Добавляйте в Слова все измерения, с которыми планируете работать.
- Имейте в виду, что созданное Слово определяет числовые потоки и напрямую ассоциировано с ними.
Моделирование.
Создание читаемых идентификаторов – Слов Cyfertalk , разбивает привычные операционные бизнес-процессы(закупка, выпуск, переработка, отгрузка и т.п.) на элементарные операции, что позволяет собирать информационную картину подобно мозаике – кусочек за кусочком.
Чтобы достичь желаемого аналитического эффекта, - необходимо заполнить достаточный минимум данных, который можно определить по сводным значениям и балансам.
При заполнении модели следует учесть несколько правил:
- Старайтесь следовать порядку и логике событий.
- Придерживайтесь принципа: "Всё что мне нужно – в пределах экрана".
- Не создавайте лишних периодов.
- Используйте воображение.
- Пользуйтесь справкой.
- Регулярно сохраняйтесь.
В заключение добавлю, что в основе успешной работы с Cyfertalk лежит эксперимент и опыт. Чем больше вы строите модели и пробуете новые подходы – тем быстрее вы начнёте получать реальную пользу и удовольствие от бизнес-калькулятора Cyfertalk .
- Создание Алфавита
- Создание Словаря
- Моделирование
Создание Алфавита.
Как можно понять из определения, Алфавит Cyfertalk - это набор специальных комбинаций символов, в терминологии Cyfertalk - Букв(признаков объектов и операций, помогающих точно определять объект и процесс.)
Буквы могут иметь один из трёх типов: группа, база и мера.
- Буквы с типом "группа" предназначены для определения признаков, которые объединяют объекты в группы. Это могут быть операции над объектами(приход, расход), определители данных(план, факт) и любые другие признаки группировки(продукты, сырьё, материалы, цеха, машины и т.д).
- Буквы с типом "база" предназначены для определения объектов. Это могут быть как конкретные объекты(|у_ТПК-3| - уголь ТПК разрез-3), так и отдельные признаки(|угл| - уголь, |Т|-Тощий, |ПК| - размер плита/крупный, |рзрз-3| - разрез-3)
- Буквы с типом "мера" предназначены для определения единиц измерения, в которых измеряются объекты. Один объект зачастую имеет несколько единиц измерения, например уголь измеряется вагонами, тоннами, килограммами, кубическими метрами и деньгами – рублями, евро, долларами и т.д.
- Буквы с типом "база" предназначены для определения объектов. Это могут быть как конкретные объекты(|у_ТПК-3| - уголь ТПК разрез-3), так и отдельные признаки(|угл| - уголь, |Т|-Тощий, |ПК| - размер плита/крупный, |рзрз-3| - разрез-3)
- Буквы с типом "мера" предназначены для определения единиц измерения, в которых измеряются объекты. Один объект зачастую имеет несколько единиц измерения, например уголь измеряется вагонами, тоннами, килограммами, кубическими метрами и деньгами – рублями, евро, долларами и т.д.
Различные комбинации Букв трёх типов образуют конечные идентификаторы бизнес процессов – Слова Cyfertalk , поэтому при разработке Алфавита, следует представлять, как Буквы будут комбинироваться и образовывать Слова.
Для разработки Слов существуют свои инструменты – формы Клонирования и Мутации, однако точность и правильность конечных идентификаторов могут гарантировать только верные порядок и содержание Алфавита.
Прежде чем приступать к построению Алфавита стоит уяснить несколько правил:
- Создавая модель, отталкивайтесь от целей её построения.
Чётко формулируйте вопросы, на которые хотите получить ответы.
Если вы хотите узнать прибыльность отдельно взятого товара – вносите только те признаки, которые влияют конкретно на этот товар.
Если вы хотите проанализировать совокупность процессов – используйте максимальное количество уже полученных суммарных данных, - не перегружайте модель лишними расчётами.
Если вам удастся достигнуть баланса между подробным описанием и использованием суммарных данных, работа в Cyfertalk принесет вам необходимый экономический эффект и удовольствие.
Если вы хотите узнать прибыльность отдельно взятого товара – вносите только те признаки, которые влияют конкретно на этот товар.
Если вы хотите проанализировать совокупность процессов – используйте максимальное количество уже полученных суммарных данных, - не перегружайте модель лишними расчётами.
Если вам удастся достигнуть баланса между подробным описанием и использованием суммарных данных, работа в Cyfertalk принесет вам необходимый экономический эффект и удовольствие.
- Продумывайте наперед, какие операции будут производиться над объектами.
Например, операции прихода и расхода производятся в 99% случаев, эти признаки скорее всего пригодятся и стоит создать соответствующие Буквы.
Если вы хотите оценивать эффективность бизнес-процессов, старайтесь разделять плановые и фактические данные.
Например сделайте первые Буквы в Словах|П|(План) и|Ф|(Факт), чтобы точно понимать какие данные относятся к плану, а какие к факту, и иметь возможность их сравнить вычитая потоки друг из друга.
Если вся модель является плановой, такой необходимости может и не быть. В любом случае отталкивайтесь от целей моделирования.
Если вы хотите оценивать эффективность бизнес-процессов, старайтесь разделять плановые и фактические данные.
Например сделайте первые Буквы в Словах|П|(План) и|Ф|(Факт), чтобы точно понимать какие данные относятся к плану, а какие к факту, и иметь возможность их сравнить вычитая потоки друг из друга.
Если вся модель является плановой, такой необходимости может и не быть. В любом случае отталкивайтесь от целей моделирования.
- Прежде чем приступать к конструированию Слов – точно выстраивайте Буквы по порядку(Вид), так как Буквы в Слове будут выстраиваться согласно номеру их Вида.
Слова Cyfertalk названы словами из-за их свойства читаемости. Например, если вы создали Буквы |План| и |Приход| - лучше всего будет сделать номер Вида |План| меньше номера Вида |Приход|, чтобы при объединении их в Слово, |План| шёл перед |Приход|. Это позволит добиться наилучшей читаемости.
Старайтесь также сокращать гласные, и сохранять согласные, чтобы добиться большей компактности Слова. Например:
можно прочитать следующим образом – План прихода продукта "уголь тощий" в размере плита/крупный в тоннах.
Если задать номер Вида неправильно(например |Прих| идёт раньше |Плн|, а |Угль| идёт раньше |Прод|) то читаемость такого Слова пострадает -
– получилось: "приход план уголь продукт..." . Как можно видеть, - из читаемого Слова такой идентификатор превращается в абракадабру.
Хотя он всё ещё может быть прочитан, лёгкость восприятия уже потеряна.
Старайтесь также сокращать гласные, и сохранять согласные, чтобы добиться большей компактности Слова. Например:
Плн|Прих|Прод|Угль|Т|ПК|тонн
можно прочитать следующим образом – План прихода продукта "уголь тощий" в размере плита/крупный в тоннах.
Если задать номер Вида неправильно(например |Прих| идёт раньше |Плн|, а |Угль| идёт раньше |Прод|) то читаемость такого Слова пострадает -
Прих|Плн|Угль|Прод|Т|ПК|тонн
– получилось: "приход план уголь продукт..." . Как можно видеть, - из читаемого Слова такой идентификатор превращается в абракадабру.
Хотя он всё ещё может быть прочитан, лёгкость восприятия уже потеряна.
- Старайтесь избегать лишних Букв.
Например, если у вас всего один товар – уголь ТПК, нет смысла создавать уточняющие его свойства Буквы: |Угль|,|Т|,|ПК|, будет достаточно одной, например просто |ТПК|.
Если же товаров несколько и они ранжируются по характеристикам, - наоборот есть смысл создать сообразные им Буквы. Например, вы производите полиэтиленовые пакеты разной длины и ширины:
Ширины 24 см, 32 см, 40 см, Длины 37 см, 40 см, 50 см
Тогда определяющие их Слова могут выглядеть примерно следующим образом:
Такое разбиение характеристик может быть очень полезно при фильтрации и выборе процессов в дальнейшем, когда вы будете строить представления модели.
Если же товаров несколько и они ранжируются по характеристикам, - наоборот есть смысл создать сообразные им Буквы. Например, вы производите полиэтиленовые пакеты разной длины и ширины:
Ширины 24 см, 32 см, 40 см, Длины 37 см, 40 см, 50 см
Тогда определяющие их Слова могут выглядеть примерно следующим образом:
Плн|Расх|Прод|24|37|кг | Плн|Прих|Прод|32|40|шт | Плн|Расх|Прод|40|50|шт |
Плн|Расх|Прод|24|40|шт | Плн|Прих|Прод|32|50|руб | И подобные... |
И последнее – прежде чем приступать к конструированию Слов, тщательно проверьте достаточность наполнения Алфавита , чтобы не приходилось создавать дополнительные Буквы уже в процессе моделирования.
Создание Словаря.
Словарь, как можно понять из его названия – это набор Слов(идентификаторов бизнес-процессов).
Порядок создания Слов может быть любым, проще всего начать с тех же Слов, с которых вы хотите начать создание первого представления модели(например: поступление оборудования, приход средств от инвесторов, выпуск продукта и т.д и т.п).
При конструировании Слов, стоит придерживаться нескольких правил:
- Подбирайте состав Слова максимально точно, не пропуская необходимых Букв и не добавляя лишних.
К данному правилу стоит отнестись особенно, так как именно состав Слова определяет бизнес-процесс, его свойства и восприятие идентификации.
Например, Слово Плн|Прих|Склд8|СМ2|М300| – определяет кем(СМ2-вторая смена), куда(Склд8 - восьмой склад) и что(М300 – цемент марки М300) планируется(Плн-план) принять(Прих-приход).
Насколько необходима каждая Буква – зависит от целей модели. Если в контексте модели, - вам важно, в какую смену поступит цемент, - то Буква |СМ2| справедливо должна быть добавлена в идентификатор.
Если же в рамках создаваемой модели вам нужно лишь рассчитать поступление к определённым дням, без учёта складов, смен и по факту, тогда будет вполне достаточно следующей идентификации: Прих|М300|.
Если мы производим цемент в одном тех-процессе, - понятно что это наш цемент, где и как он произведён, и дополнительных Букв не требуется. Однако, если мы покупаем цемент или производим в разных цехах/тех-процессах, - стоит добавлять соответствующие Буквы.
Например: Прих|Euro|М500| - Приход от OOO "Евроцемент" марки М500.
Отнеситесь с должной внимательностью к составлению Слов, так как исправить их невозможно.
Слова Прих|Euro|М500| и Прих|М500| - отражают разные процессы, и соответственно к ним относятся разные числовые потоки.
Если Прих|Euro|М500| обозначает количество прихода марки М500 именно от OOO "Евроцемент", то Прих|М500| - количество всего прихода М500 от всех компаний, и одно Слово никак не может превратиться в другое.
Например, Слово Плн|Прих|Склд8|СМ2|М300| – определяет кем(СМ2-вторая смена), куда(Склд8 - восьмой склад) и что(М300 – цемент марки М300) планируется(Плн-план) принять(Прих-приход).
Насколько необходима каждая Буква – зависит от целей модели. Если в контексте модели, - вам важно, в какую смену поступит цемент, - то Буква |СМ2| справедливо должна быть добавлена в идентификатор.
Если же в рамках создаваемой модели вам нужно лишь рассчитать поступление к определённым дням, без учёта складов, смен и по факту, тогда будет вполне достаточно следующей идентификации: Прих|М300|.
Если мы производим цемент в одном тех-процессе, - понятно что это наш цемент, где и как он произведён, и дополнительных Букв не требуется. Однако, если мы покупаем цемент или производим в разных цехах/тех-процессах, - стоит добавлять соответствующие Буквы.
Например: Прих|Euro|М500| - Приход от OOO "Евроцемент" марки М500.
Отнеситесь с должной внимательностью к составлению Слов, так как исправить их невозможно.
Слова Прих|Euro|М500| и Прих|М500| - отражают разные процессы, и соответственно к ним относятся разные числовые потоки.
Если Прих|Euro|М500| обозначает количество прихода марки М500 именно от OOO "Евроцемент", то Прих|М500| - количество всего прихода М500 от всех компаний, и одно Слово никак не может превратиться в другое.
- Добавляйте в Слова все измерения, с которыми планируете работать.
Пусть лучше некоторые измерения останутся неиспользованными, чем необходимых измерений не окажется в Слове.
- Имейте в виду, что созданное Слово определяет числовые потоки и напрямую ассоциировано с ними.
У каждого Слова есть измерения, каждое из которых определяет один числовой поток. Например, у Слова Прих|Прод|БсМ(Приход продукта булка с маком) есть три измерения – шт(штуки), кг(килограммы) и руб(рубли), соответственно данное Слово способно дать три числовых потока, которые отражают динамику прихода булки с маком.
Если удалить Слово Прих|Прод|БсМ – то удалятся и ассоциированные с ним потоки.
Не стоит стремиться создать все возможные Слова, прежде чем приступать к моделированию Пресетов(настроек-наборов Слов). Достаточно создать те, которые точно будут участвовать в представлении и расчётах.
Если удалить Слово Прих|Прод|БсМ – то удалятся и ассоциированные с ним потоки.
Не стоит стремиться создать все возможные Слова, прежде чем приступать к моделированию Пресетов(настроек-наборов Слов). Достаточно создать те, которые точно будут участвовать в представлении и расчётах.
Моделирование.
Создание читаемых идентификаторов – Слов Cyfertalk , разбивает привычные операционные бизнес-процессы(закупка, выпуск, переработка, отгрузка и т.п.) на элементарные операции, что позволяет собирать информационную картину подобно мозаике – кусочек за кусочком.
Чтобы достичь желаемого аналитического эффекта, - необходимо заполнить достаточный минимум данных, который можно определить по сводным значениям и балансам.
При заполнении модели следует учесть несколько правил:
- Старайтесь следовать порядку и логике событий.
Вся архитектура Cyfertalk преследует цель построения максимально приближенной к реальности симуляции.
Поэтому при заполнении потоков значениями, создании Формул и Пресетов стоит опираться на реальные события и операции.
Например, если ваша модель предназначена для анализа сделки с новым клиентом (вы хотите понять сколько оборотных средств и на какой срок будет заморожено, какой может быть прибыль, сколько заложить на риск) – начинайте заполнение с расходов на закупку сырья(если у вас производство)/товаров(если у вас трейдинговая компания).
Точно так же как это должно происходить в реальности, - сначала расход со счёта, затем ожидание подтверждения от поставщика, через определённое в договоре время – поставка, после поставки – обработка(производство/перепаковка/маркировка/и т.п.), затем получение оплаты и отгрузка.
Таким образом, всё, что от вас требуется – это тщательно заполнять данные, следуя логике бизнес-процесса. В результате вы получите нужные результаты – даты возможных разрывов кэш-фло, нехватки ресурсов, необходимые суммы покрытия и т.п.
Поэтому при заполнении потоков значениями, создании Формул и Пресетов стоит опираться на реальные события и операции.
Например, если ваша модель предназначена для анализа сделки с новым клиентом (вы хотите понять сколько оборотных средств и на какой срок будет заморожено, какой может быть прибыль, сколько заложить на риск) – начинайте заполнение с расходов на закупку сырья(если у вас производство)/товаров(если у вас трейдинговая компания).
Точно так же как это должно происходить в реальности, - сначала расход со счёта, затем ожидание подтверждения от поставщика, через определённое в договоре время – поставка, после поставки – обработка(производство/перепаковка/маркировка/и т.п.), затем получение оплаты и отгрузка.
Таким образом, всё, что от вас требуется – это тщательно заполнять данные, следуя логике бизнес-процесса. В результате вы получите нужные результаты – даты возможных разрывов кэш-фло, нехватки ресурсов, необходимые суммы покрытия и т.п.
- Придерживайтесь принципа: "Всё что мне нужно – в пределах экрана".
Стремитесь свести представление к минимуму строк числовых потоков.
Например, не стоит мешать в одну кучу процессы закупки, выпуска, отгрузки и подобные макро-процессы. Разместите их в разных Пресетах, а для сведения используйте суммарные формулы.
Кроме того, при необходимости вы всегда можете быстро включить/выключить нужные вам потоки.
Например, не стоит мешать в одну кучу процессы закупки, выпуска, отгрузки и подобные макро-процессы. Разместите их в разных Пресетах, а для сведения используйте суммарные формулы.
Кроме того, при необходимости вы всегда можете быстро включить/выключить нужные вам потоки.
- Не создавайте лишних периодов.
Так как база Cyfertalk растёт по мере обращения к новым периодам, - не переключайтесь на те периоды, что вам не нужны, чтобы не перегружать базу данных и систему расчётов.
Например, если ваша модель рассчитана на год, начиная с 01.01.2044 по 01.01.2045, - не стоит переключаться на предыдущие(31.12.2043 и меньше) и последующие(01.02.2045 и больше) даты.
Например, если ваша модель рассчитана на год, начиная с 01.01.2044 по 01.01.2045, - не стоит переключаться на предыдущие(31.12.2043 и меньше) и последующие(01.02.2045 и больше) даты.
- Используйте воображение.
При работе в Cyfertalk некоторые тривиальные задачи могут быть решены нестандартными способами.
К примеру для заполнения потоков числами можно создать формулу-заполнитель(так и назвать её-"заполнитель"). Рассчитанные в такой формуле значения можно копировать в поток процесса при помощи функции копирования(белая стрелочка слева от Слова(наименования потока)потока в Главном планшете).
Или, например, для визуального выделения потока из общего массива можно применить функцию выделения для копирования по дням: Ctrl + правая кнопка мыши в поле Слова(наименования потока).
При обретении некоторого опыта, очень вероятно что вы найдёте не один такой "лайфхак".
К примеру для заполнения потоков числами можно создать формулу-заполнитель(так и назвать её-"заполнитель"). Рассчитанные в такой формуле значения можно копировать в поток процесса при помощи функции копирования(белая стрелочка слева от Слова(наименования потока)потока в Главном планшете).
Или, например, для визуального выделения потока из общего массива можно применить функцию выделения для копирования по дням: Ctrl + правая кнопка мыши в поле Слова(наименования потока).
При обретении некоторого опыта, очень вероятно что вы найдёте не один такой "лайфхак".
- Пользуйтесь справкой.
Вызвать справку текущего окна можно нажав F1 либо знак вопроса в углу окна.
- Регулярно сохраняйтесь.
Делайте архивные копии перед массовыми изменениями модели, это позволит откатиться назад, если что-то пойдёт не так.
Так же можно пользоваться быстрым сохранением(F5) и быстрой загрузкой(F9), быстро сохраняя/загружая всю модель в промежуточное сохранение.
Так же можно пользоваться быстрым сохранением(F5) и быстрой загрузкой(F9), быстро сохраняя/загружая всю модель в промежуточное сохранение.
В заключение добавлю, что в основе успешной работы с Cyfertalk лежит эксперимент и опыт. Чем больше вы строите модели и пробуете новые подходы – тем быстрее вы начнёте получать реальную пользу и удовольствие от бизнес-калькулятора Cyfertalk .
#17
Справка и часто задаваемые вопросы / Термины и понятия
Последний ответ от Администратор - Дек. 10, 2022, 03:13В системе приняты следующие термины, необходимые для понимания внутренних механизмов работы и более ясного взаимодействия с элементами интерфейса:
1. Числовой поток - последовательность чисел во временном разрезе, где пересечение семантического идентификатора и определённой даты представляет собой ячейку, в которой хранится число.
2. Буква - сочетание символов естественного языка и/или иных символов, допустимых для использования приложением.
Проще говоря, Буква Cyfertalk - это несколько букв обычного(естественного) языка и/или иных символов, за которыми стоит обозначение какого-то объекта/признака/свойства.
Например Буква ПЛН - обозначает "план", а Буква "ФКТ" - "факт".
В качестве Буквы Cyfertalk может выступать и одна естественная буква("П") и естественное слово целиком("план") или же буквенно-численный код("П8%").
Буквы Cyfertalk нужны для построения Слов Cyfertalk и бывают трёх типов - Группа, База и Мера.
Группа обозначает признаки потока, например, - его направление, принадлежность и прочие подобные характеристики, отражающие сущность объединения объектов потоков(план/факт, приход/расход, Склад/цех/путь, продукт/сырьё/материал и подобное), то есть те признаки, по которым должна производится группировка.
База обозначает те характеристики, сочетание которых будет уникально его идентифицировать(Вид сырья, ширина/высота, цвет, номер счёта, № смены, и подобное), то есть те признаки, которые достоверно указывают на поток.
Мера - это сокращение от единицы измерения(кг,шт,руб и подобное), то есть конечный идентификатор, определяющий поток как таковой, и хотя Слово одно, оно может быть выражено несколькими мерами:
рождая таким образом несколько потоков в разных измерениях.
ПЛН|Прих|ПРДкт|склд| & кг руб шт,
рождая таким образом несколько потоков в разных измерениях.
3. Алфавит - реестр всех Букв.
4. Слово - семантический идентификатор числовых потоков.
Слово представляет из себя подобие естественного слова, и предназначено для идентификации числовых потоков в системе Cyfertalk .
Как в естественном языке слова обозначают понятия из жизни людей, так Слова Cyfertalk обозначают понятия из жизни бизнеса.
Слова Cyfertalk составляются из Букв Cyfertalk посредством объединения через разделитель "|".
Например: ПЛН|Прих|ПРДкт|склд|кг - план прихода продукта на склад в килограммах.
Закодированные в Буквах Cyfertalk - Слова Cyfertalk позволяют определять групповые принадлежности бизнес-процессов, их признаки, свойства, а также единицы измерения, определяющие числовые потоки материальных объектов, будь то товары, сырьё, деньги или что-то ещё.
Такое построение позволяет визуально идентифицировать числовые потоки, что многократно упрощает работу с ними.
Как в естественном языке слова обозначают понятия из жизни людей, так Слова Cyfertalk обозначают понятия из жизни бизнеса.
Слова Cyfertalk составляются из Букв Cyfertalk посредством объединения через разделитель "|".
Например: ПЛН|Прих|ПРДкт|склд|кг - план прихода продукта на склад в килограммах.
Закодированные в Буквах Cyfertalk - Слова Cyfertalk позволяют определять групповые принадлежности бизнес-процессов, их признаки, свойства, а также единицы измерения, определяющие числовые потоки материальных объектов, будь то товары, сырьё, деньги или что-то ещё.
Такое построение позволяет визуально идентифицировать числовые потоки, что многократно упрощает работу с ними.
5. Словарь - реестр Слов. В Словаре содержатся все созданные пользователем Слова, с расшифровками их Букв.
6. Набор - сохраненная выборка Слов или формул.
7. Пресет - сохранённый Набор Слов и/или формул.
8. Ячейка - поле для значения потока на конкретную дату.
9. Строкообразующая - Слово по конкретной единице измерения. Например: ПЛН|Прих|ПРДкт|склд|руб
Как можно понять из вышеописанных терминов, система идентификации Cyfertalk - есть шаг в следующее измерение языка, в котором сочетания букв/символов - сами являются Буквами, а сочетания (сокращённых)слов - Словами.
Такая архитектура имеет ряд преимуществ перед традиционными системами обработки данных.
Во-первых, вы работаете напрямую с числовыми потоками, а не статичными значениями. Вместо постоянного поиска нужных значений, вы просто выбираете нужные Строкообразующие и строите на их основе отчёты, планы, аналитику в любом виде и за любые периоды.
Во-вторых, такие идентификаторы читаются, что упрощает взаимодействие и распознание принадлежности чисел.
И в-третьих, она позволяет организовать удобную выборку, сортировку и фильтрацию числовых потоков по Буквам Cyfertalk для любых целей, будь то сборка прогноза, отчёта или комплексный анализ.
Во-вторых, такие идентификаторы читаются, что упрощает взаимодействие и распознание принадлежности чисел.
И в-третьих, она позволяет организовать удобную выборку, сортировку и фильтрацию числовых потоков по Буквам Cyfertalk для любых целей, будь то сборка прогноза, отчёта или комплексный анализ.
При небольшом навыке данную методику можно с лёгкостью применить для мониторинга, планирования и анализа всех трудовых процессов, способных быть выраженными численно.